
Why UUID Primary Keys Slow SQLite (And What to Do Instead)
UUIDs offer convenience. They make records globally unique, enable easy merging between systems, and avoid centralized ID generation. That convenience, though, comes with a cost—especially in SQLite, where the database engine, storage layout, and typical usage patterns collide with UUID semantics to produce surprising performance regressions. This article walks through the technical reasons UUID primary keys are costly in SQLite, shows the observable impacts, and gives practical, tested alternatives and mitigation strategies so you can have global uniqueness without shooting yourself in the foot.

SQLite database file icon
Choosing the right primary key is a systems decision: small choices at the schema level ripple into IO, memory, and latency.
How SQLite stores rows and why that matters
SQLite is a compact, file-based database with a simple but efficient storage model. Every table has an implicit rowid unless you declare WITHOUT ROWID. When you declare an INTEGER PRIMARY KEY, SQLite aliases that column to the rowid and stores rows in the table's B-tree ordered by that value. That ordering makes new inserts efficient when their keys are monotonically increasing: new rows append near the end of the B-tree, minimizing page splits and keeping related data close on disk.
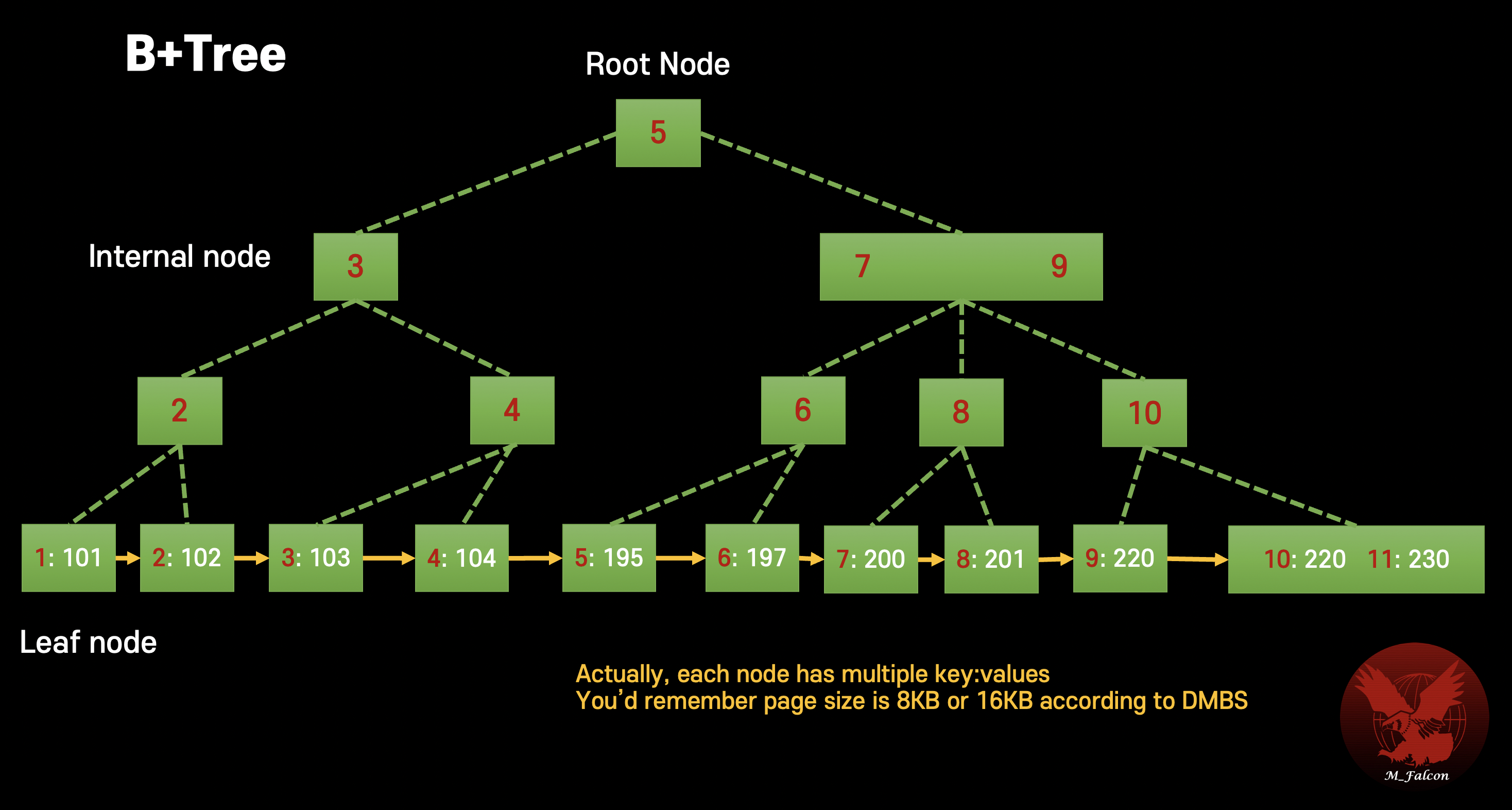
B-tree database structure diagram
UUIDs commonly used as primary keys—especially v4 random UUIDs—are, by definition, random. A random key breaks that natural insert order. Instead of appending, each insert may belong in a different B-tree page. The result: frequent page splits, scattered writes, higher index depth, and more random IO. In short, random keys transform efficient sequential writes into an expensive pattern of random writes.
SQLite INTEGER PRIMARY KEY
Concrete performance effects of UUID primary keys
When you use UUIDs as the primary key in SQLite, expect a combination of the following effects:
- Increased database size: Random inserts spread data across pages, leaving more partially filled pages and increasing file size.
- Slower insert throughput: Page splits and random writes slow down inserts, often by multiple times versus sequential integer keys.
- Poor cache utilization: The page cache sees lower locality of reference, increasing page reads from disk.
- Deeper indexes: More levels in the B-tree increase lookup time and maintenance cost on writes.
- Write amplification in WAL mode: WAL files and checkpoints work harder because operations touch many pages.
These are not theoretical problems: in embedded devices or serverless deployments where storage and memory are constrained, the gap between a UUID-keyed table and an INTEGER PRIMARY KEY table can be dramatic—orders of magnitude in some workloads.

UUID GUID visual representation
Why storage format matters: TEXT vs BLOB vs INTEGER
Developers store UUIDs in different ways: as TEXT (36 characters with hyphens), as a compact 32-char string, or as a 16-byte BLOB. Each choice has trade-offs:
- TEXT uses more bytes per index entry and compares lexicographically, increasing index size and affecting memory usage.
- BLOB (16 bytes) is compact and usually faster for comparisons, but still random.
- INTEGER (8 bytes) is ideal for SQLite's rowid aliasing—the database is optimized to leverage integer primary keys for clustered storage.
So even if you store a UUID as a 16-byte BLOB, the randomness remains the core problem. Compactness helps, but it doesn't restore locality.
Row clustering and WITHOUT ROWID tables
SQLite supports WITHOUT ROWID tables, which store table data directly in the primary key's B-tree and can reduce overhead for wide tables. If you use UUIDs as the primary key on a WITHOUT ROWID table, you still face the random insert problem, because the physical ordering remains keyed on your UUID values. The difference is that WITHOUT ROWID removes the extra rowid indirection and can reduce storage overhead, but it doesn't make random keys behave like sequential ones.

SQLite WITHOUT ROWID table
How page splits and B-tree behavior amplify the problem
Imagine a B-tree page that is 4KB and holds multiple rows. Sequential inserts push new rows to the current rightmost page until it fills. Random inserts frequently need to place a row into a partially full page in the middle of the tree. That forces a page split: SQLite splits the page into two and redistributes entries. Page splits are expensive because they cause additional writes and increase tree height over time.

database fragmentation illustration
In write-heavy apps, frequent page splits translate into higher latency and more disk IO. On flash storage, that also increases wear. Crunching more data per write costs CPU cycles and increases contention in multi-threaded scenarios.
Real-world analogies and quick mental models
Think of an append-only journal versus a shuffled deck. Appending to a journal is cheap: you write at the end. Writing into a shuffled deck requires searching the exact position, disturbing the deck, and reordering cards. UUIDs shuffle the deck. INTEGER primary keys append to the journal.
If your writes are the majority of traffic, clustering matters more than uniqueness scheme elegance.
When UUIDs are still the right choice
UUIDs have real advantages. Use cases where UUIDs are reasonable include:
- Systems that must generate globally unique identifiers offline and merge records later.
- APIs where clients create resources and the server must accept externally generated IDs.
- Multi-master replication scenarios where coordinating a central ID allocator is impractical.
Even when these constraints exist, you can minimize performance pain without abandoning UUIDs altogether. The next section outlines concrete alternatives and mitigations.
Practical alternatives and migration strategies
There are several strategies to achieve the best of both worlds: the uniqueness of UUIDs and the performance of sequential keys.
1. Use INTEGER PRIMARY KEY and keep UUID as a secondary unique column
This is often the simplest and most effective approach. Let SQLite use its rowid/INTEGER PRIMARY KEY for clustered storage and index maintenance, and store the UUID in a separate column with a UNIQUE constraint. Reads by UUID still use the index, but the table remains clustered by insertion order.
Benefits:
- Best insert and range-scan performance.
- Smaller index on the primary storage B-tree.
- UUID uniqueness preserved for distributed systems.
2. Use monotonic or time-prefixed UUIDs (ULID, UUIDv1, UUIDv6)
Many UUID variants incorporate time so new values are roughly increasing. ULID and newer UUID versions (v1 includes timestamp and MAC, v6 is a time-ordered variant) reduce randomness at insertion time. Time-ordered identifiers keep new inserts near the tree's edge, dramatically reducing page splits.
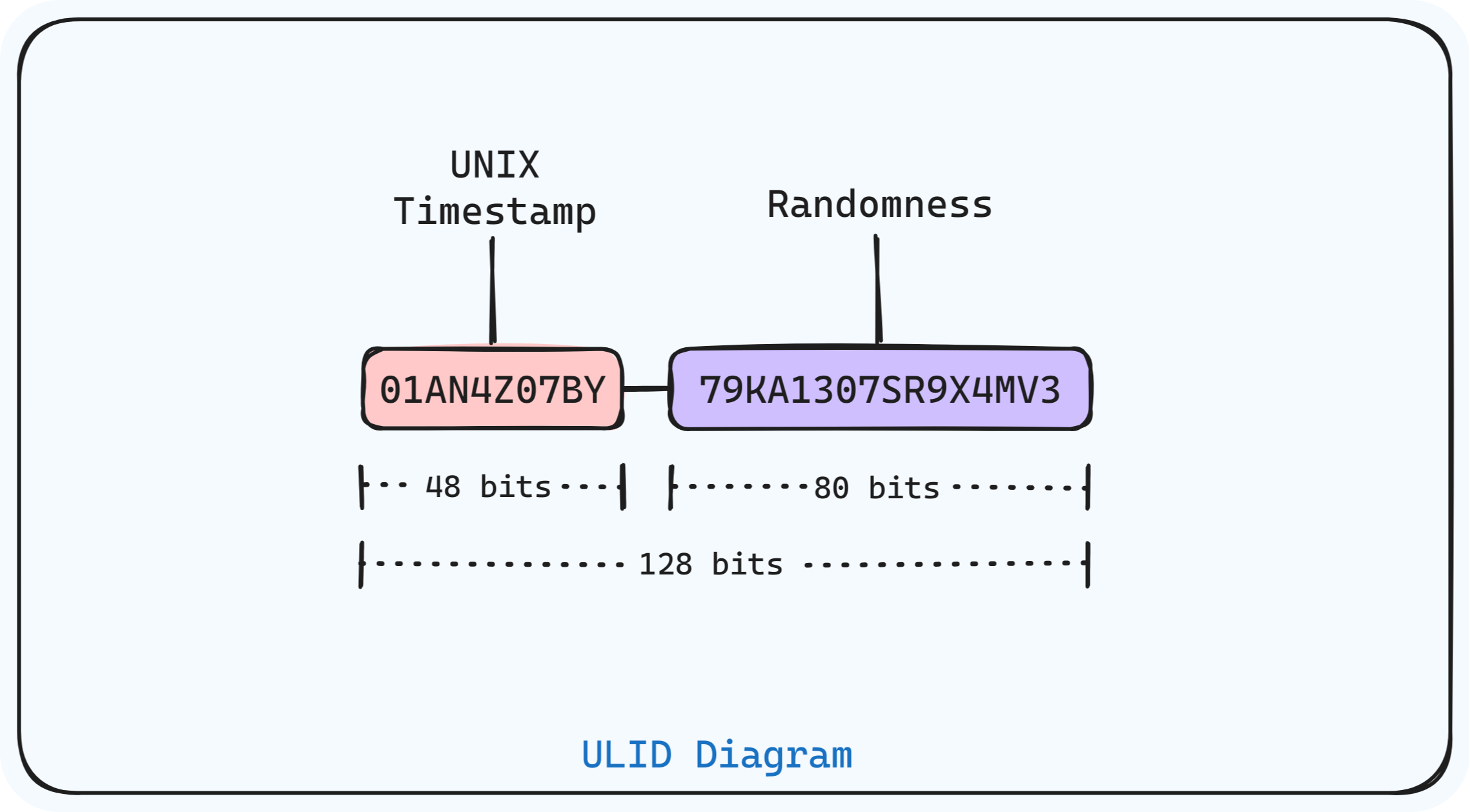
ULID monotonic UUID format
Trade-offs: time-based UUIDs leak timestamp information (a privacy concern in some contexts), and v1 requires node identifiers which can expose machine fingerprints unless care is taken. ULIDs are a practical middle ground for monotonic behavior and simplicity.
3. Use a COMB GUID approach
COMB GUIDs embed timestamp bits into otherwise-random GUIDs to make them partially ordered. The idea is to keep the global uniqueness of GUIDs while adding insertion locality. COMB-style values are a pragmatic compromise used in many systems that want to keep UUID-like IDs but improve insert locality.
Operational mitigations and SQLite tuning
If you inherit a schema with UUID primary keys or must keep them for functional reasons, you can reduce the damage with operational techniques:
- Batch inserts inside transactions — group writes to reduce checkpoint frequency and WAL overhead.
- Adjust page_size — larger page sizes can reduce splits for wide rows, though they increase memory usage.
- Use WAL mode — PRAGMA journal_mode=WAL reduces writer/reader contention and gives better concurrency for many workloads.
- Run VACUUM and ANALYZE periodically — reclaim free space and let the query planner make better choices.
- Consider PRAGMA incremental_vacuum if your database experiences chronic fragmentation.
None of these fully remove the root cause—random ordering—but they can reduce write amplification and latency spikes.
Migration pattern: safely convert a UUID PK to an INTEGER PK
Turning a UUID primary key into an INTEGER primary key is a common migration. A safe pattern:
- Add a new INTEGER column with AUTOINCREMENT or let it be an alias to rowid by declaring it as INTEGER PRIMARY KEY in a new table.
- Populate the new table by copying rows from the old one, preserving the UUID column.
- Create UNIQUE index on the UUID column in the new table to preserve semantic constraints.
- Swap tables (or use a transactional rename) and drop the old table when safe.
This approach preserves public UUIDs and references while cutting the structural costs. Always test on a copy of your production data and ensure backups before schema migrations.
Benchmarks, measurement, and what to watch
Measure before you change: collect baseline metrics for insert throughput, average latency, WAL size, cache hit ratio, index size on disk, and overall database file size. After changes, compare those same metrics. Important indicators of UUID pain include:
- Rising average insert latency as table grows.
- Disproportionate WAL growth for a given write volume.
- Large index file size compared to number of rows.
- High page cache misses visible when you instrument with PRAGMA stats or your hosting environment metrics.
Good measurement tools include application-level timing, OS-level IO statistics, and periodic SQLite PRAGMA outputs such as page_count and freelist_count.
Measure first, hypothesize second—many perceived performance problems are actually solvable with tuning rather than schema changes.
Edge cases and gotchas
A few non-obvious behaviors to keep in mind:
- Foreign key references: If many small tables reference a UUID primary key, each referencing index also grows larger and incurs the same maintenance cost on inserts and deletes.
- Concurrency: SQLite's concurrency model benefits from minimizing write contention—faster inserts via sequential keys reduce locking windows.
- Backups and replication: Larger, more fragmented files take longer to copy, increasing RPO for file-based backups.
Decision checklist: choose the right approach
Ask these questions before committing to UUID primary keys:
- Do clients need to generate IDs offline?
- Is global uniqueness required at creation time, or can it be achieved later?
- Is insert throughput and small-file footprint more important than ID aesthetics?
- Can you store a UUID as a secondary indexed column instead of the clustered primary key?
If answers lean toward local generation and global uniqueness is only occasionally needed, prefer INTEGER primary keys and keep UUIDs as secondary columns. If global, offline uniqueness is non-negotiable, prefer monotonic UUIDs or hybrid approaches.
Conclusion
UUIDs are a powerful tool for uniqueness and distributed systems, but in SQLite they interact poorly with the storage engine's assumptions about clustered, sequential keys. Random UUID primary keys increase index size, fragment data, produce excessive page splits, and slow insert-heavy workloads. Fortunately, you don't need to choose strictly between performance and uniqueness. Practical alternatives—INTEGER primary keys with UUID secondary columns, monotonic UUIDs (ULID/UUIDv1/v6), COMB GUIDs, and schema/operation tuning—let you regain performance while keeping the global uniqueness you depend on.
- Avoid random UUIDs as SQLite primary keys when insert performance and compact storage matter.
- Prefer INTEGER PRIMARY KEY for clustered storage and keep UUIDs as indexed secondary columns if you need external uniqueness.
- If UUIDs are required, use time-ordered UUIDs or store them as BLOBs and consider using a surrogate integer key in the table.
- Measure and tune using PRAGMA and real workload benchmarks before and after schema changes.
If you design your schema with storage behavior in mind, you keep both the performance your users feel and the uniqueness your architecture requires.