
Nanobot: The Ultra-Lightweight Personal AI Assistant
Imagine an AI that fits in your pocket, respects your privacy, and wakes instantly without a cloud hop. That is the promise of Nanobot: an ultra-lightweight personal AI assistant engineered specifically for edge devices, mobile phones, wearables, and even constrained microcontrollers. This article walks through what Nanobot means in practice — the engineering trade-offs, the user experience implications, the privacy benefits, and where such tiny, fast assistants will matter most as AI migrates off the large data center and onto the devices we hold every day.

Nanobot on-device AI assistant
Why "ultra-lightweight" matters
When people talk about AI assistants they often mean large models running in the cloud: powerful, versatile, but slow to wake, data-hungry, and dependent on network connectivity. Ultra-lightweight assistants invert that paradigm. They are built to be small in memory footprint, economical in compute, and designed to operate locally. The result is a different product promise: instant responses, offline availability, and stronger control over personal data. For users who value responsiveness and privacy more than general knowledge breadth, Nanobot-style assistants deliver a superior experience.
What is Nanobot?
A definition
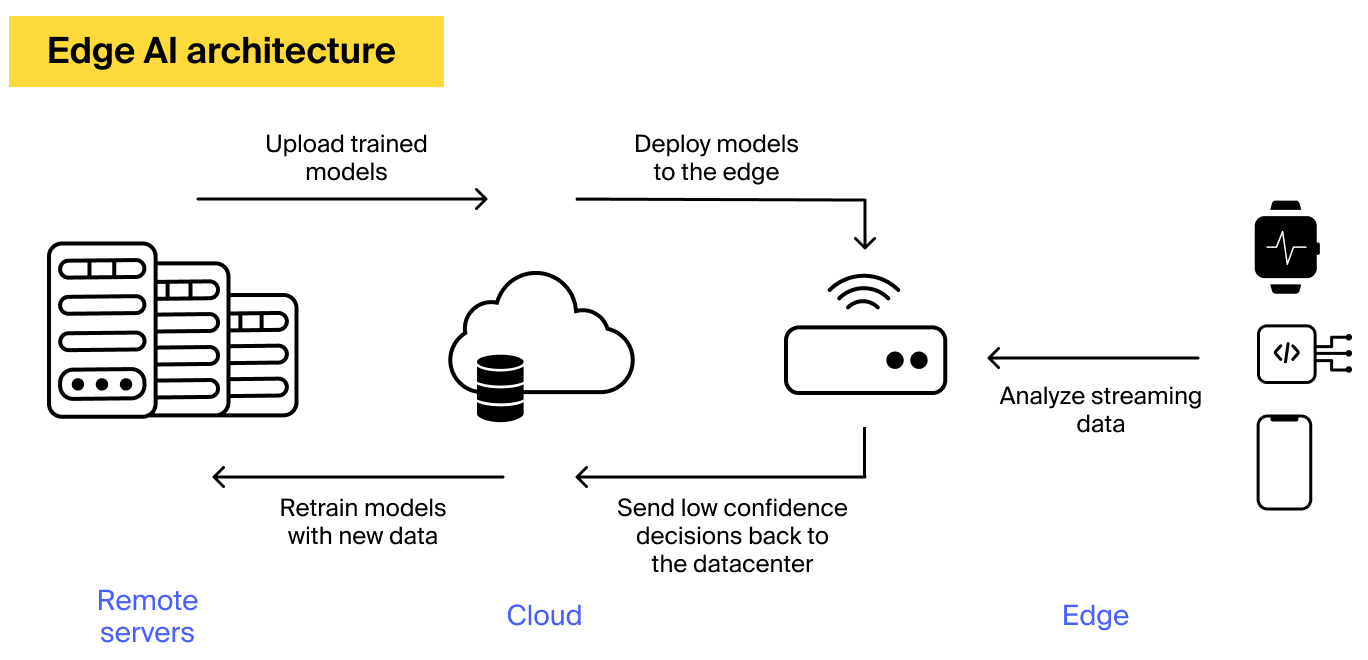
edge AI assistant architecture
Core characteristics
Nanobot is defined by four core characteristics: tiny model size, modular capability, local-first execution, and personalization. Tiny model size means parameter counts far lower than large foundation models; modular capability means separate compact modules for tasks like intent detection, slot-filling, language generation, and action execution; local-first execution means inference happens on device whenever possible; personalization means models adapt to the user's language, routines, and preferences without sending raw data off-device.
Speed and privacy win when the assistant is already in your device — no cloud round-trip required.

privacy-first AI assistant
How Nanobot works under the hood
Tiny models, big engineering
Delivering meaningful assistance with a small model is achievable through a set of established engineering techniques: model distillation, quantization, pruning, and architecture design optimizations. Distillation transfers knowledge from a large teacher model into a compact student model. Quantization reduces numerical precision to compress size and speed up math operations. Pruning removes redundant parameters. Combined, these techniques can shrink models by an order of magnitude while preserving most of the task-specific intelligence users care about.

local AI assistant on mobile
Hybrid modular design
Nanobot prefers a modular pipeline over a single monolithic model. A fast intent classifier identifies the user's goal; a small retrieval or memory module fetches relevant information (local calendar, recent messages, device sensors); a compact generator formulates the response; and an action layer executes commands. Modularization lets engineers optimize each component for latency, accuracy, and energy consumption. It also enables graceful degradation: if complex language generation is too expensive, Nanobot falls back to templated or retrieval-based replies that are cheap and reliable.

tiny models for AI assistants
Real-world use cases
Everyday productivity
For most users, a personal assistant is about practical tasks: creating reminders, summarizing recent messages, drafting quick replies, or extracting highlights from a meeting. Nanobot excels at these: local calendar access plus a compact summarizer can produce meeting notes instantly; a tiny parser can fill calendar slots from a voice command; a quick template generator can compose replies without network latency. The result is a frictionless workflow where help is fast and context-aware.
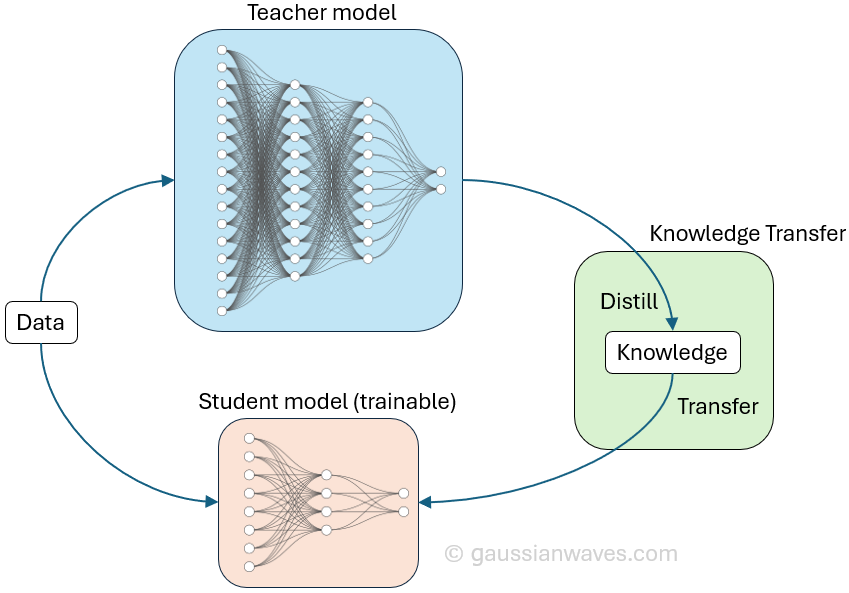
model distillation for Nanobot
Privacy-first interactions
Some tasks simply shouldn't leave the device. Private conversations, financial details, or health information benefit from local processing. Nanobot can store and process sensitive data locally, exposing only anonymized or aggregated signals when necessary. This design reduces regulatory and reputational risk while offering the user stronger control over their digital footprint.

quantization techniques for AI
Always-on sensors and ambient intelligence
Wearables and IoT devices can pair with Nanobot to offer proactive assistance: surfacing context-aware prompts, completing hands-free tasks, or adapting notifications to the user's current activity. Because Nanobot runs locally, it can continuously analyze sensor data without heavy battery penalties, helping it decide when to interrupt the user or remain silent.
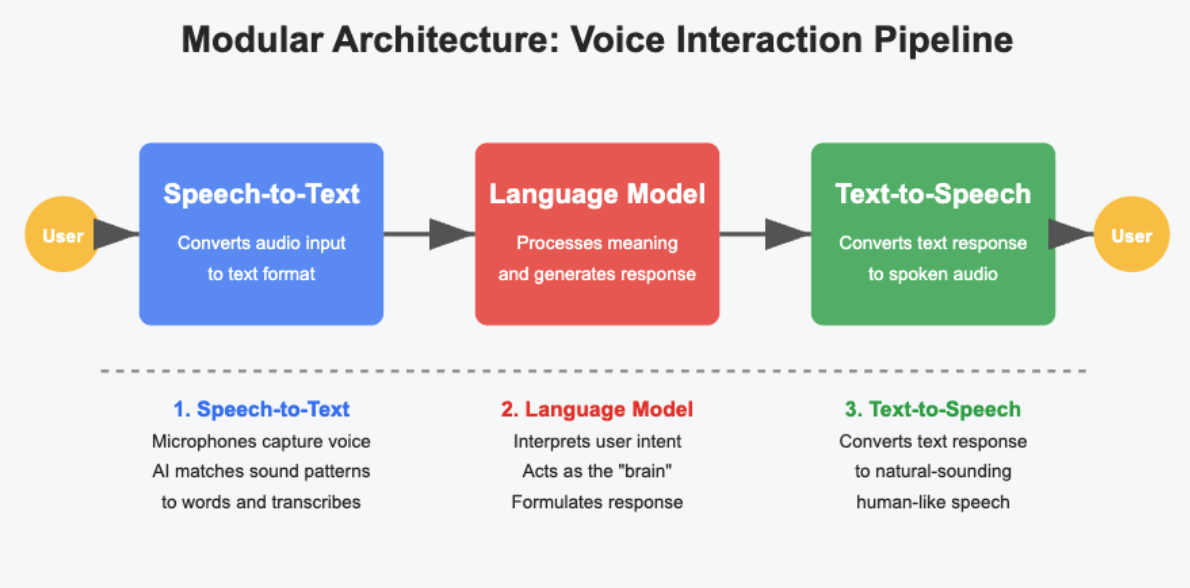
modular pipeline for AI assistants
Design trade-offs and limitations
Breadth vs depth
By necessity, Nanobot trades off open-domain knowledge for speed and privacy. It will not rival large cloud models when asked obscure trivia or to generate lengthy creative prose. But for the tasks that comprise most assistant usage — short-form responses, task automation, and device control — the performance is often indistinguishable to users, and the latency and privacy gains outweigh the narrower knowledge scope.
Compute and battery constraints
Even optimized models consume power and compute. Designers must balance responsiveness with battery life. Nanobot handles this by using low-power accelerator hardware when available, batching background tasks, and dynamically adjusting model fidelity: full inference for active interactions, lighter heuristics for passive monitoring.
- Instant responses with local inference.
- Stronger privacy because sensitive data stays on-device.
- Offline availability for many core features.
- Limited general knowledge compared to cloud models.
- Hardware variability means inconsistent performance across devices.
- Update complexity for improving models in the field.
Developer and deployment considerations
Packaging and updates
Delivering Nanobot to users involves packaging compact models with runtime libraries that are small and secure. Updates present a challenge: models must be refreshed to improve accuracy or add features, but frequent large downloads defeat the lightweight goal. Delta updates, modular patches, and server-assisted personalization (where only non-sensitive model deltas are delivered) are practical strategies. Some vendors also offer secure model-hosting services that provide occasional capability boosts without moving raw user data off-device.

federated learning for personalization
Developer tooling
Successful adoption depends on developer-friendly tools: model compilers that optimize to target hardware, APIs for connecting the assistant to device sensors and apps, and sandboxing mechanisms to preserve user privacy. A small ecosystem of middleware that converts high-level intents into platform-specific actions will be essential for real-world integration.
Comparing Nanobot to cloud-first assistants
When local beats cloud
Local-first assistants win when latency, privacy, or offline operation is paramount. Mobile users in low-connectivity environments, professionals handling confidential information, and wearable use cases that require instant feedback are natural fit scenarios. Even when cloud access is available, local assistants reduce network costs and improve reliability.
When cloud still matters
Cloud models retain advantages for large-scale knowledge retrieval, heavy-duty reasoning, and complex multimodal generation. A hybrid architecture — where Nanobot handles routine tasks locally and consults cloud services for exceptional queries — often yields the best user experience. That hybrid approach preserves responsiveness while offering an escape hatch to richer capabilities when needed.
Nanobot wearable integration
Real-world examples and scenarios
A day with Nanobot
Morning: Nanobot reads a short, private summary of your calendar and highlights action items extracted from yesterday's messages. Commute: a local route summarizer suggests the fastest path and mutes non-urgent alerts. Work: Nanobot creates a meeting agenda from recent notes, drafts a short reply to a colleague based on your writing style, and toggles focus mode on your device. Evening: it compiles a privacy-preserving health summary from wearable data and offers gentle wind-down suggestions without uploading raw sensor logs to the cloud.
Industry adoption
We are already seeing sectors where Nanobot-style assistants make sense: healthcare devices that must protect patient data, industrial IoT where connectivity is intermittent, and consumer wearables where battery life and privacy are competitive advantages. As silicon improves and software tooling matures, the range of feasible on-device AI tasks will expand rapidly.
The future roadmap for Nanobot
Smarter personalization
Personalization is central to the Nanobot promise. Future iterations will use federated learning and private aggregation to tune models across millions of devices without centralizing raw user data. The goal is assistants that understand individual preferences deeply while keeping the data anchored on-device.
Hardware acceleration and standards
Continued advances in mobile NPUs, DSPs, and specialized tinyML accelerators will expand what Nanobot can do. Standardized model formats and runtimes will make deployment across device types easier, reducing fragmentation and lowering the barrier for developers building personal assistants.
Conclusion
The Nanobot concept reframes the AI assistant from a distant cloud service to a personal, on-device companion. It trades limitless breadth for speed, privacy, and reliability — characteristics that matter in daily interactions. For users who want instant help, fewer network dependencies, and tighter control over their data, ultra-lightweight assistants are more than a technical curiosity: they are the next wave of practical AI. The technology is already capable of delivering meaningful value today, and as hardware and privacy-preserving techniques mature, expect Nanobot-style assistants to become a standard part of our devices and daily workflows.
- Nanobot is an on-device, ultra-lightweight assistant focused on speed, privacy, and efficiency.
- Architectural choices like model distillation, quantization, and modular design are central to its success.
- It complements cloud AI by handling everyday tasks locally and escalating to the cloud only when necessary.
Nanobot — small models, practical assistance, big impact.