
Gemini 3.1: Why It's the Most Intelligent AI Model Today
The assertion that "Gemini 3.1 is the most intelligent model at the moment" is attention-grabbing, and for good reason. In this deep feature we parse that claim with nuance: what intelligence means for modern models, where Gemini 3.1 shines, where it still struggles, and why its emergence matters. Readers will find a clear explanation of the model's capabilities, how those capabilities are measured, practical implications for developers and organizations, and what to watch next.
UNDERSTANDING 'INTELLIGENCE' IN AI
The word intelligence is seductive but slippery. In the context of large language models and multimodal systems, intelligence is a bundle of abilities: advanced reasoning, factual recall, coherent long-form composition, contextual adaptability, cross-modal understanding (text, images, code), and predictable safety behavior. No single metric perfectly captures all of these, which is why leaders in the field are judged on a constellation of tests and real-world outcomes rather than a single score.
Defining practical intelligence
When practitioners call a model "intelligent," they usually mean it can solve new problems with minimal instruction, maintain coherent multi-turn dialogues, reason about complex scenarios, and produce reliable outputs across diverse domains. A truly intelligent model is not simply a parrot of training data; it generalizes, composes knowledge, and adapts its style and approach to the user's intent.
WHAT IS GEMINI 3.1?
Gemini 3.1 represents a generational improvement in multimodal large models. It is designed to integrate text, images, and structured data in ways that improve reasoning and context retention. The design emphasis is on robust multi-step reasoning, improved factuality, and better handling of instruction-following tasks. Those characteristics explain why many evaluations and early adopters have touted its performance as leading-edge.
Multimodal integration
One key distinguishing feature of Gemini 3.1 is smoother multimodal understanding. That means it can accept an image and a block of text together, reason about them jointly, and produce answers that reference both modes coherently. In practical terms, this is what enables tasks like accurately describing visual data, diagnosing problems from screenshots, or generating code snippets that reason about both a user's textual requirements and a companion diagram.

multimodal AI Gemini 3.1
A model's intelligence is measured less by flash demonstrations and more by consistent, repeatable problem solving across form factors and domains.
PERFORMANCE AND BENCHMARKS
How do we know a model is "most intelligent"? The community uses benchmarks as one useful piece of evidence: reasoning tests, coding exams, standardized question sets, multilingual understanding tasks, and specialized challenges like mathematical problem-solving. Gemini 3.1 consistently ranks near or at the top across a variety of these benchmarks—especially those designed to test multi-step reasoning and multimodal comprehension.
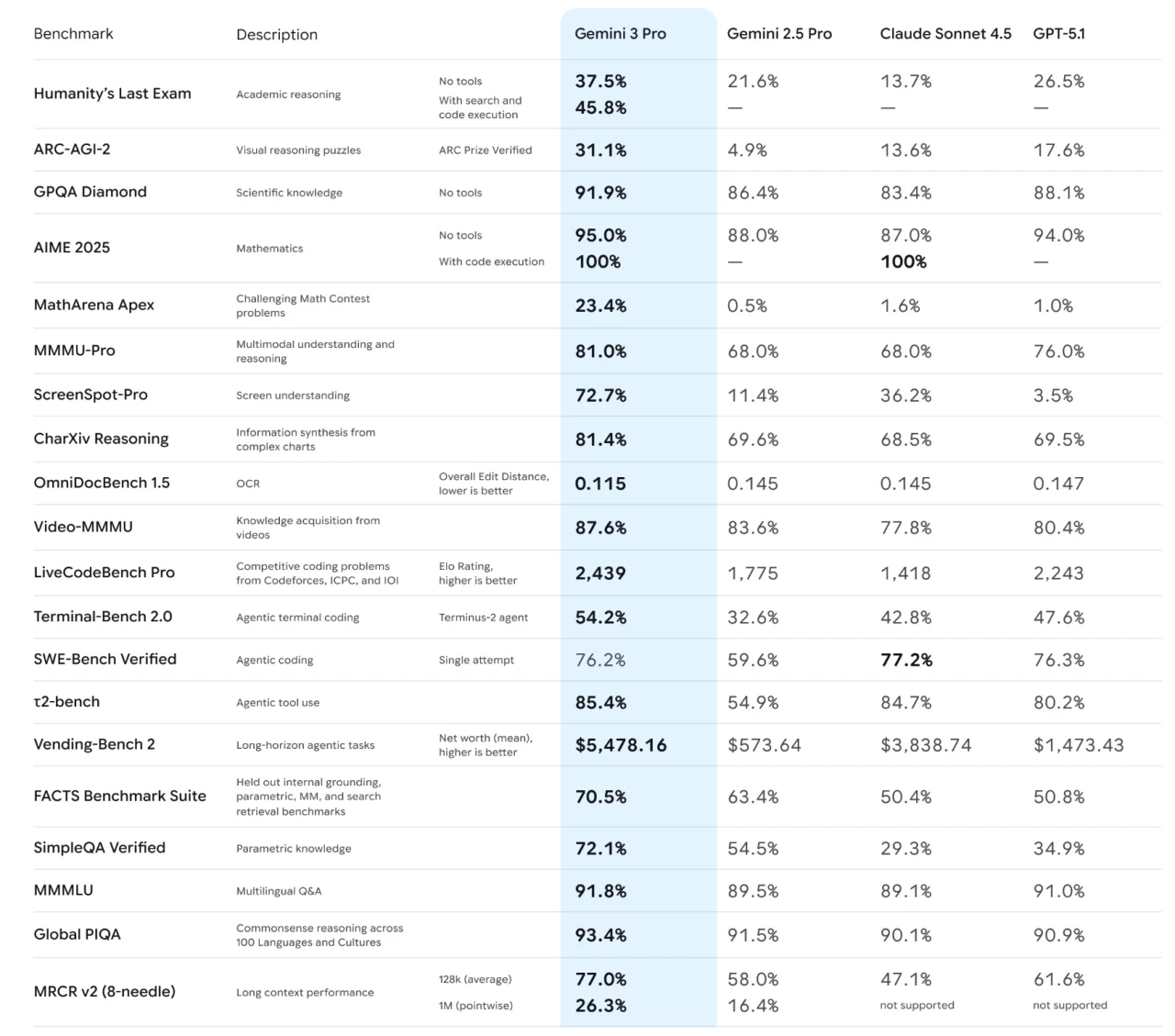
Gemini 3.1 benchmarks
Reasoning and chain-of-thought
Gemini 3.1 is noted for its improved ability to follow and produce chain-of-thought reasoning. That means it can justify intermediate steps when solving a problem, which both improves correctness and gives users insight into how the model arrived at an answer. For developers, that transparency is invaluable—especially in high-stakes applications such as legal summarization or scientific assistance.
chain-of-thought reasoning AI
Multilingual and domain breadth
Another area of strength is multilingual performance. Gemini 3.1 handles many languages with high fidelity, not merely in surface translation but in cultural pragmatics and idiomatic usage. It also shows strong domain breadth: from coding and technical writing to creative tasks and business analysis, the model demonstrates adaptability that rivals the best alternatives.

multilingual AI Gemini 3.1
ARCHITECTURE, TRAINING, AND DESIGN TRADEOFFS
At its core, Gemini 3.1 applies advanced transformer architectures with innovations tuned for multimodal fusion and reasoning. Training involved large, diverse datasets and targeted fine-tuning to improve instruction-following and reduce hallucinations. Important engineering decisions—tokenization choices, context window size, and how multimodal signals are fused—directly impact practical intelligence.
Did You Know? The way a model encodes an image versus text influences its ability to reason across modalities. Features learned early in training can have outsized effects on downstream reasoning tasks.
Safety and alignment mechanisms
Intelligence without safeguards can be dangerous. Gemini 3.1 incorporates alignment work—reward modeling, human feedback loops, and policy-aware filters—to reduce harmful outputs and improve usefulness. While no model is perfectly aligned, improvements in instruction tuning and guardrails make Gemini 3.1 safer in many interactive settings.

AI model safety alignment
REAL-WORLD USE CASES
The practical impact of Gemini 3.1 appears across industries. Its strengths in multimodal reasoning and reliable instruction-following unlock tangible user-facing improvements rather than merely academic wins.
Developer productivity and code generation
Developers benefit from models that understand problem context, produce accurate code snippets, and debug interactively. Gemini 3.1 shows improved accuracy in code generation and explanation, reducing the time engineers spend correcting or validating outputs.

Gemini 3.1 code generation
Enterprise knowledge work
Enterprises leverage models like Gemini 3.1 for summarization, analysis, and decision support. Its ability to synthesize long documents, extract action items, and reason across structured and unstructured data makes it valuable in legal, finance, and healthcare settings—where clarity and traceability matter.
- Advanced reasoning: Better chain-of-thought and multi-step problem solving.
- Multimodal: Strong joint text-image understanding.
- Instruction-following: More reliable outputs for tasks and workflows.
- Compute intensity: High-resource training and inference costs.
- Residual hallucinations: Not immune to factual errors.
- Access constraints: Enterprise gating may limit broad experimentation.
LIMITATIONS, RISKS, AND ETHICAL CONCERNS
No model is omniscient. Even leading-edge systems have weaknesses that matter in practice.
Hallucination and factuality
Gemini 3.1 reduces hallucination compared with earlier models in its lineage, but it still fabricates at times—especially when asked for highly specific, obscure facts. Users should validate critical outputs and design systems that flag or verify uncertain responses.
AI hallucination and factuality
Bias and fairness
Like all models trained on large-scale human data, Gemini 3.1 inherits biases from its training corpus. Responsible deployment requires auditing for fairness, adjusting prompts, and using post-processing checks to prevent disproportionate harms.
Caution In regulated contexts—medical diagnosis, legal advice, or financial recommendations—these models should augment qualified professionals, not replace them.
COMPARISON WITH OTHER LEADING MODELS
Claims of being "the most intelligent" hinge on comparisons. Rather than a blanket victory, Gemini 3.1 tends to lead in areas like multimodal reasoning and instruction-following, while other models might excel in specific niches—low-latency inference, smaller-footprint deployment, or specialized domain tuning.
Benchmarks versus reality
Benchmarks provide signals but not the whole story. Real-world robustness, latency, integration costs, and the quality of developer tooling all influence which model is the best fit for a particular product or workflow.
DEPLOYMENT, COSTS, AND OPERATIONAL CONSIDERATIONS
Leading models bring engineering burdens. High-performing models often require significant compute for inference and optimized infrastructure to meet latency targets. Organizations must weigh the increased capability against hardware costs, API pricing, and the personnel required to operate and monitor the model at scale.
Gemini 3.1 deployment costs
Scaling and inference strategies
Approaches like model quantization, distillation, and hybrid architectures can reduce costs while retaining much of the intelligence. For many use cases, a combination of a powerful central model for complex tasks and lightweight models for routine queries will be the most economical architecture.
DEVELOPER EXPERIENCE AND ECOSYSTEM
A model's technical merits are amplified or diminished by the ecosystem around it. Documentation, SDKs, prompt templates, and community examples accelerate adoption. Gemini 3.1 has benefited from robust tooling that helps engineers integrate multimodal capabilities into applications with fewer friction points than previous generations.
Prompt engineering and instruction design
Effective use of sophisticated models still depends on prompt design. Good prompts guide the model's chain-of-thought, reduce ambiguity, and steer outputs toward required formats. The best developer practices combine clear prompts, validation rules, and human-in-the-loop review for sensitive tasks.
BUSINESS IMPLICATIONS
For businesses, advancing to a model like Gemini 3.1 can unlock new product categories: interactive assistants that can draw from documents and images, automated workflows that understand complex specifications, or analytics products that translate visual data into narrative insights. Early adopters gain competitive advantage, but they also take on the responsibility of setting safety and governance standards.
Competitive differentiation
Companies that integrate advanced models thoughtfully can differentiate by delivering more natural, context-aware experiences. However, differentiation depends on combining model capability with domain expertise, data pipelines, and UX design—not merely on the model itself.
FUTURE OUTLOOK
Intelligence in AI models is evolving rapidly. Future iterations will push on longer-context reasoning, improved memory, tighter factual grounding, and more efficient multimodal fusion. These advances will make models more useful and reduce some of the current risks—but they will also raise new governance and societal questions.
Pro Tip For organizations experimenting with advanced models, start with narrow, high-value workflows where verification and human oversight are straightforward. Scale gradually while measuring both business KPIs and safety metrics.
CONCLUSION
Calling Gemini 3.1 "the most intelligent model" captures a real shift: improved multimodal reasoning, stronger instruction-following, and better real-world usability. But intelligence is multifaceted. The model excels in many arenas yet remains bounded by costs, residual hallucinations, and the need for careful governance.
Practical intelligence is judged by consistent problem solving and safe integration into real workflows—not sensational demos.
- Gemini 3.1 advances multimodal reasoning and instruction-following, earning it top marks across many benchmarks.
- Strengths include chain-of-thought clarity, multilingual capability, and domain breadth; weaknesses include cost, potential hallucination, and inherited bias.
- Successful adoption requires tooling, human oversight, and deployment strategies that balance capability with safety and cost.
Final thought
Models like Gemini 3.1 are not a singular destination; they are a step in a rapidly moving landscape. The immediate winner is not only the model itself but the organizations that pair leading capabilities with responsible practices—those will deliver the most meaningful, sustainable value.
Illustration: Conceptual representation of multimodal reasoning and human-AI collaboration.