Do Transformers Need Three Projections? QKV Variants Explained
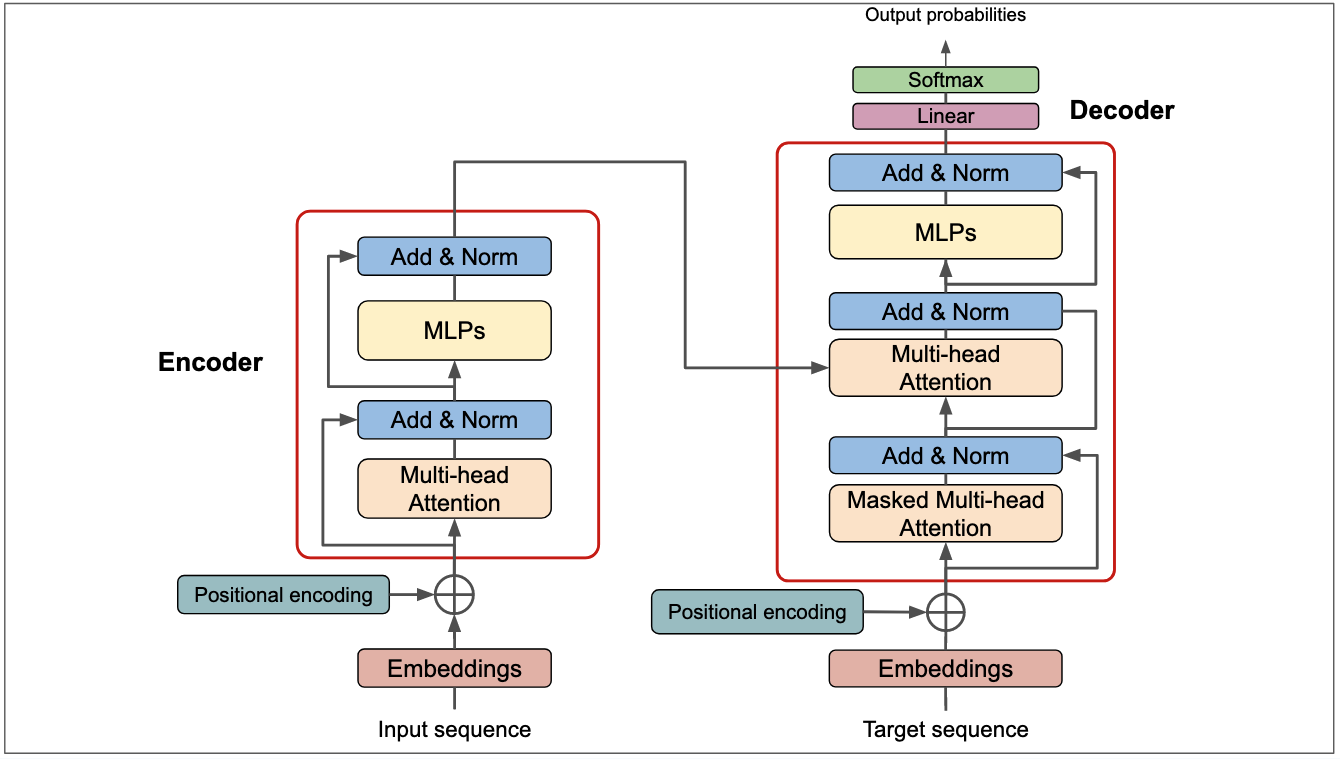
The transformer revolution hinged on a deceptively simple building block: scaled dot-product attention. At the heart of that block are three learned linear projections—Queries (Q), Keys (K), and Values (V)—that together enable flexible, content-based mixing across tokens. But do we really need three separate projections? Researchers and practitioners have experimented with tying, merging, or removing projections to reduce parameter count, speed up inference, or probe model expressivity. This article unpacks the math, the empirical trade-offs, the practical implementation choices, and the situations where fewer than three projections are not just viable but advantageous.
transformer QKV attention mechanism
Why Q, K, and V in the First Place
Mechanics of the classic attention
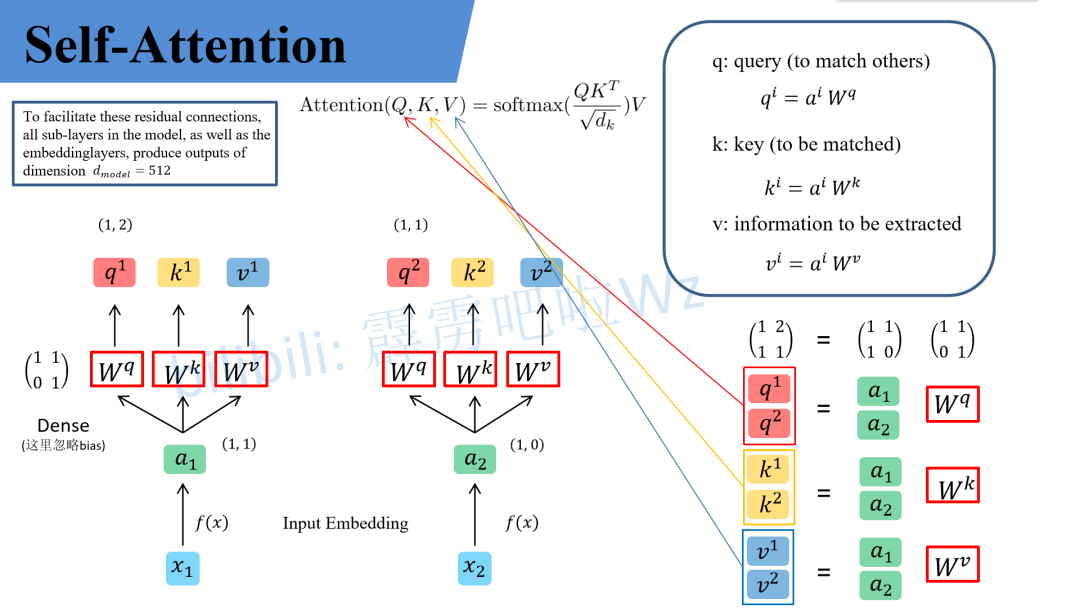
In the canonical transformer, each input token x is transformed into three vectors: q = W_q x, k = W_k x, and v = W_v x (ignoring biases for clarity). Attention scores are computed from pairwise dot products between queries and keys—q_i · k_j—normalized with softmax and applied to values: attention_i = softmax(q_i K^T / sqrt(d_k)) V. This separation is purposeful: queries and keys encode compatibility (who should attend to whom), while values carry the content to be aggregated.
vision transformer ViT architecture
A short intuition
Think of Keys as labels on memory slots, Queries as the search terms, and Values as the stored contents. This division lets the model learn one representation for matching and a different one for representing the information to convey. In many tasks, matching and content representation are distinct concerns—requiring different geometric encodings—and three projections give the model freedom to learn both optimally.
Separate projections let transformers decouple similarity measurement from the content being passed — that's the subtle power of QKV.
How Many Projections Do Models Actually Need?
Variants people try
Over the years the community has tested several alternatives to the three-projection standard. The main families are:
- Three separate projections (W_q, W_k, W_v) — the default in most implementations.
- Tied projections — share weights between some or all of W_q, W_k, W_v.
- Two-projection designs — combine Q and K or K and V into a single projection and derive the third via transformation.
- Single-projection / joint projection — one shared W produces a representation split into q,k,v (often by chunking the output vector).
- Factorized or low-rank projections — decompose projection matrices to reduce parameters.
BERT language model transformer
What changes when you cut projections?
Reducing projections alters three things primarily: parameter count, expressivity, and the geometry of learned representations. Sharing weights may reduce parameters and improve parameter efficiency, but it constrains the model: the same linear mapping must simultaneously produce vectors good for matching and for content. Factorization reduces rank and can speed compute on some hardware but may hurt the ability to represent complex interactions.
Mathematics and Representational Trade-offs
Degrees of freedom and linear maps
Each projection W is a matrix mapping the input space R^d to a lower-dimensional attention subspace R^d_k. With three full matrices, the model has 3*d*d_k linear degrees of freedom in the attention block (per head). Share or remove a matrix and you remove independent linear degrees of freedom. This matters: attention is ultimately a bilinear form because it pairs queries with keys; reducing degrees of freedom restricts the set of bilinear forms the model can realize.
When is reduction harmless?
If the downstream task doesn't require independent encodings for match vs. content, tying projections can be nearly lossless. For example, in some language modeling scenarios where content and similarity signals align, a shared projection that is split may still capture the needed structure. Conversely, in tasks requiring asymmetric roles—e.g., retrieval where keys are fixed indexes and queries are dynamic—separate projections shine.
GPT transformer model visualization
Empirical Findings: What Experiments Tend to Show
Typical results from ablations
Across multiple studies and practical ablations, a few consistent patterns emerge:
- Parameter-tied models often match baseline accuracy early in training and sometimes lag slightly at convergence, especially on large-scale tasks where subtle representational capacity matters.
- Two-projection designs frequently offer the best trade-off: a modest parameter reduction with minimal accuracy loss in many settings.
- Single shared projection can work surprisingly well for some tasks, particularly when followed by non-linearities or gating that enable divergent downstream processing.
- Factorized or low-rank projections help in memory-constrained deployments but sometimes require tuning rank to avoid underfitting.
Performance, speed, and hardware realities
Fewer parameters don't always mean faster inference. On GPUs and TPUs, large dense matrix multiplies are highly optimized; splitting one big matrix into several small ones can increase kernel launches and overhead. Conversely, parameter reduction matters on CPU inference or edge devices and when shipping models over networks. Also, models that tie weights may benefit from better cache locality and lower memory transfer, but profiling is essential: microbenchmarks can contradict intuition.
neural network matrix projections
Design Patterns and Practical Implementations
When to tie vs. when to keep separate
Use separate QKV projections when:
- Task complexity is high — large language models and multitask systems benefit from the extra expressivity.
- Asymmetric roles exist — encoder-decoder attention or retrieval tasks where queries and keys have different distributions.
- You have compute capacity and wish to maximize accuracy.
Consider tying or merging projections when:
- Model size is constrained — mobile or edge deployments where parameter count and model size matter.
- Dataset is moderate and you observe little benefit from expanded capacity.
- Latency on CPU matters and fewer parameters reduce memory transfers.
Implementation recipes
Some practical approaches that appear in production codebases:
- Chunked single projection: compute XW_shared to produce a concatenated vector, then split into q,k,v. Minimal code changes and weight savings.
- Pairwise tying: share W_q and W_k but keep W_v separate—keeps content representation free while tying similarity computations.
- Low-rank factorization: W = A B where A is d×r and B is r×d_k with r < d_k. Often combined with residual parameterization to recover capacity.
hardware GPU transformer optimization
Case Studies: Language vs Vision
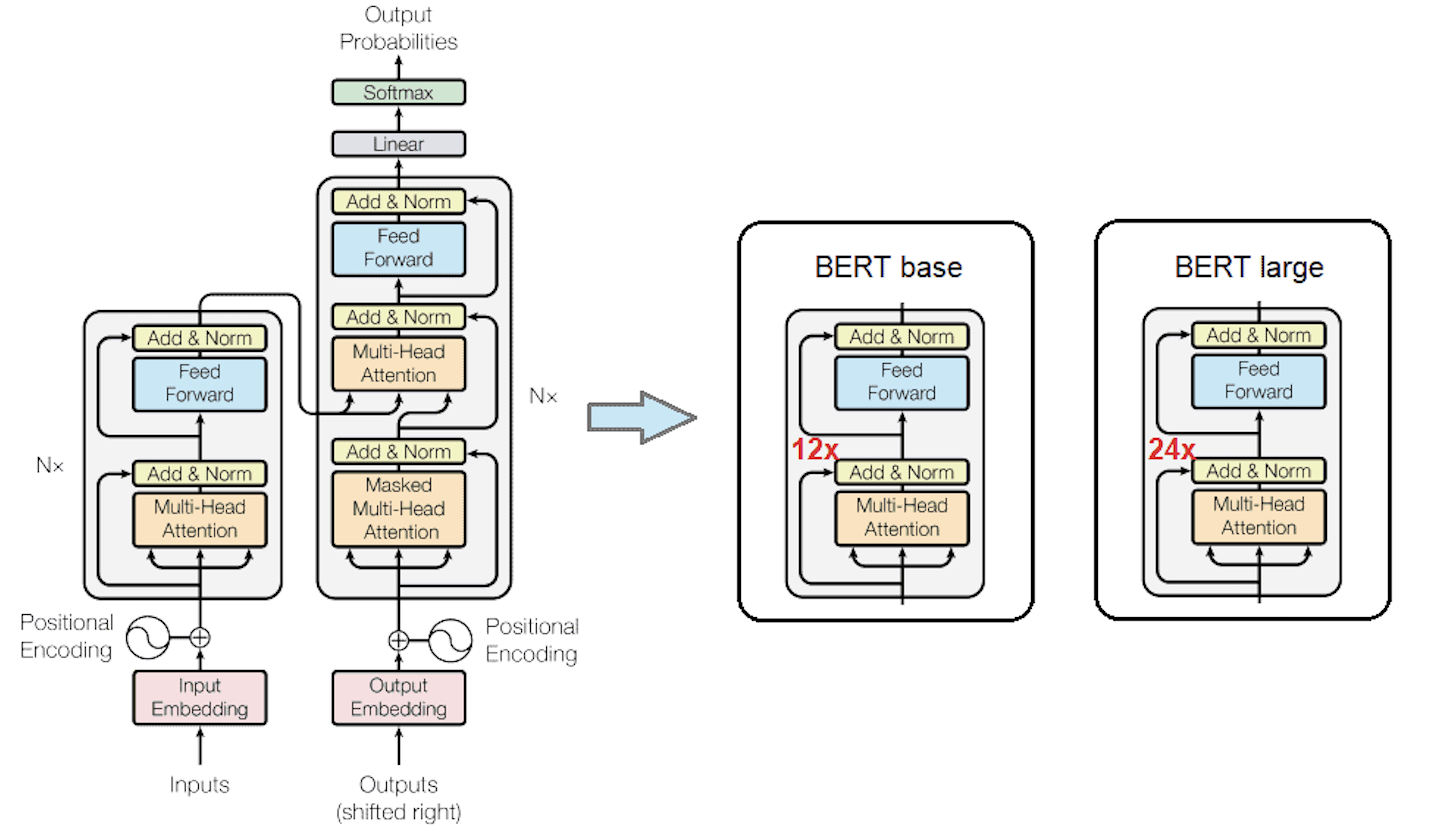
Language models
Large autoregressive and encoder–decoder language models frequently keep independent QKV matrices. Language modeling benefits from subtle distinctions between how tokens query context vs how they represent content. In many transformer LMs, tying projections can degrade perplexity unless additional capacity is introduced elsewhere.
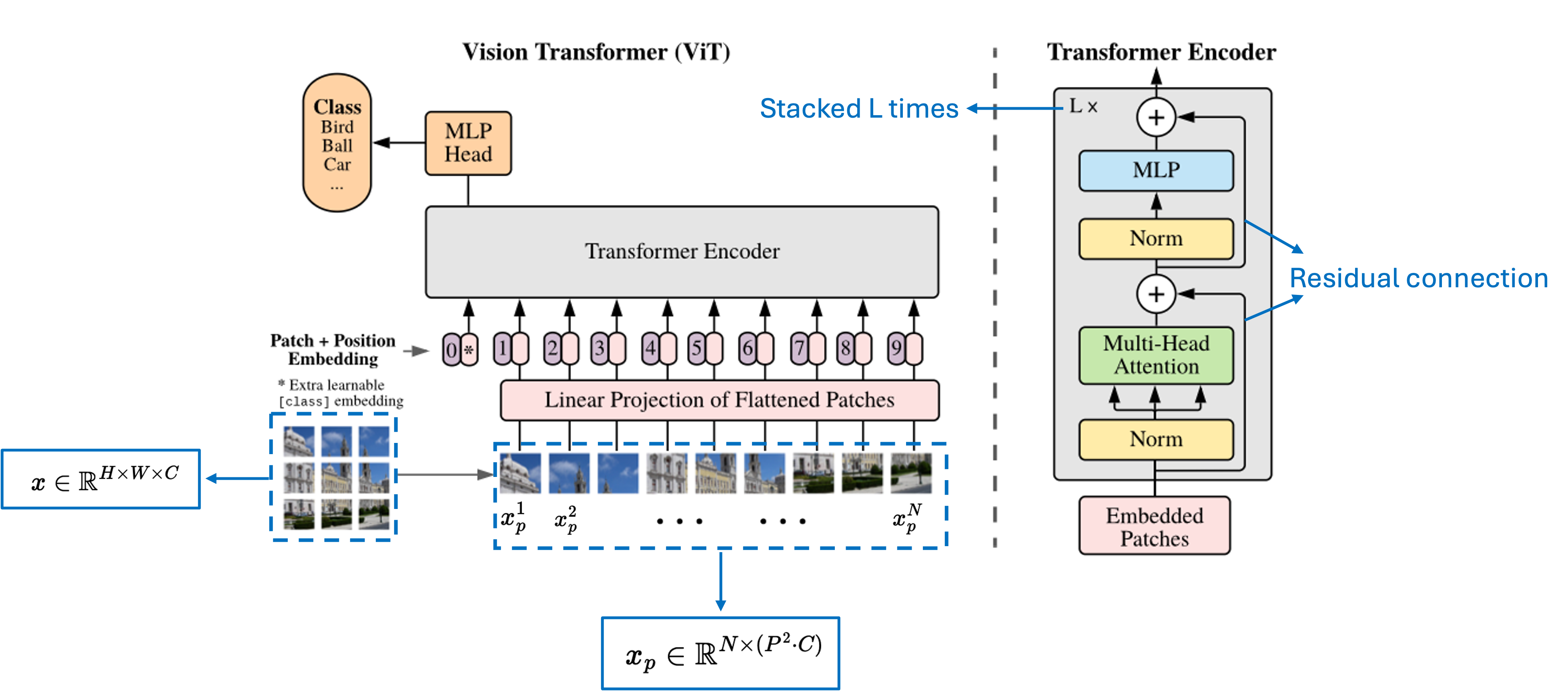
Vision transformers (ViT)
ViTs sometimes tolerate projection tying better, particularly in smaller models or when pretraining is limited. Since patch embeddings already impose a structured local representation, joint projections can be a cost-effective choice during model compression and for on-device applications.
Limitations, Risks, and Open Questions
When tying can hurt
Tied projections can produce representational entanglement: the same geometric transformations must serve matching and content roles, which can create optimization conflicts. In extreme cases, this leads to slower convergence, the need for higher learning rates, or sensitivity to initialization.
Research frontiers
Open questions include how projection design interacts with: normalization schemes, positional encodings, emergent modularity in large models, and sparsity-inducing regularizers. Another intriguing avenue is adaptive projection control—learned gates that determine when to share and when to separate projections dynamically.
Practical Checklist for Engineers
Before you change QKV
- Measure baseline performance, latency, and memory footprint.
- Profile hardware to see whether matrix math or memory transfer dominates.
- Plan tuning — changes often require retuning learning rate, warmup schedule, and weight decay.
A/B test options
- Try pairwise tying first (e.g., W_q = W_k) — often the best compromise.
- Evaluate single shared projection with non-linear post-processing (layer-specific MLPs) to recover lost expressivity.
- Consider hybrid approaches — tie in lower layers, keep separate in higher layers where abstraction matters more.
Small architectural changes in attention can produce outsized effects on convergence, compute, and downstream accuracy — measure everything.
Conclusion: Three Projections Are Often Useful — But Not Always Mandatory
The three-projection design is a robust default that gives transformers the flexibility to disentangle matching from content representation. However, it's not an inviolable law. Two-projection and single-projection alternatives offer practical gains in parameter efficiency and deployment cost in many real-world settings, provided teams accept some representational constraints and carefully retune training. The right choice depends on task complexity, compute and latency targets, and how much engineering you can invest in tuning and profiling.
- Three projections maximize expressivity and are safest for large, complex tasks.
- Tying projections reduces parameters but constrains the model and can affect convergence.
- Two-projection designs hit a pragmatic sweet spot for many deployments.
- Always benchmark latency and retrain with tuned hyperparameters after architectural changes.
Final thought
Architecture choices in deep learning are negotiations between theory, hardware, and data. QKV design is a potent example: three projections give you the theoretical breadth; fewer projections buy you focused efficiency. The best engineers treat QKV as a lever—experiment, measure, and let constraints guide the compromise.